株式会社 ソフテック
制御用ソフトウェアの受託開発を手がけて54年の経験と
受注案件7354件(2026年2月末時点)の実績
受注案件7354件(2026年2月末時点)の実績
「ソフテックだより」では、ソフトウェア開発に関する情報や開発現場における社員の取り組みなどを定期的にお知らせしています。
さまざまなテーマを取り上げていますので、他のソフテックだよりも、ぜひご覧下さい。
ソフテックだより(発行日順)のページへ
ソフテックだより 技術レポート(技術分野別)のページへ
ソフテックだより 現場の声(シーン別)のページへ
「ソフテックだより」では、みなさまのご意見・ご感想を募集しています。ぜひみなさまの声をお聞かせください。
「ベクトル量子化(Vector Quantization:以下VQと称します)」という言葉からどのような事柄を想像されますか?「ベクトルとは大きさと向きを持った値である」と勉強された方も多いかと思います。もしくは、「量子化」と聞いて物理学の量子力学を連想される方もいらっしゃるかもしれません。
今回、私はベクトル量子化の調査を担当することになり、上司のサポートを受けながらソフテック社内における新技術の調査に携わらせていただきました。
私は、学生時代に、情報圧縮について勉強したことは一切ありませんでした。そのため、ベクトル量子化がどのような技術なのか、ソフトウェアとしてどのように設計・開発すればいいのかなど、全く見当もつきませんでした。その一方で社内における新たな挑戦ということに、とても興味を抱いたことを覚えています。
今回のソフテックだよりでは、その調査結果の一部をご紹介したいと思います。
まず、VQにおけるベクトル(Vector)とは、「n次元ベクトル」を示します。nは1ベクトルあたりの成分数です。例えば、RGBの3要素を持った1ピクセルは、3次元ベクトル空間の1サンプルと考えることができます。
次に、量子化(Quantization)とは、「ある連続量を、データ量削減のために、最も近い不連続値に近似化して、値の精度を落とすこと」を言います。例えばADC(Analog Digital Converter:AD変換)においても量子化が行われます。量子化を施すことで、情報の精度は落ちますが、端数が切り捨てられるためにデータ量の削減を図ることができます。
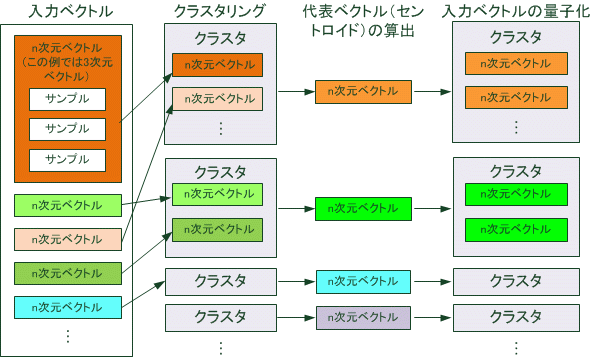
図1. ベクトル量子化の流れ
図 1はベクトル量子化の流れを示したものです。通常、VQは複数の入力サンプルをまとめてn次元ベクトルとして扱います。このベクトルが一つ以上含まれた集合を「クラスタ」と呼びます。このクラスタを任意の数にクラスタリングして量子化します。この時、クラスタ化された各グループから、クラスタを構成する各サンプルに最も近い値を持つ「代表ベクトル(セントロイド)」が作られます。クラスタ内の各サンプルは、代表ベクトルに置換されます(=量子化)。この代表ベクトルを集めたデータ集は、しばしば「コードブック(符号帳)」と呼ばれます。VQ圧縮を用いて情報伝送を行う場合には、このコードブックとその復号化のための符号列を用いて相互に情報のやりとりを行います。(図2)
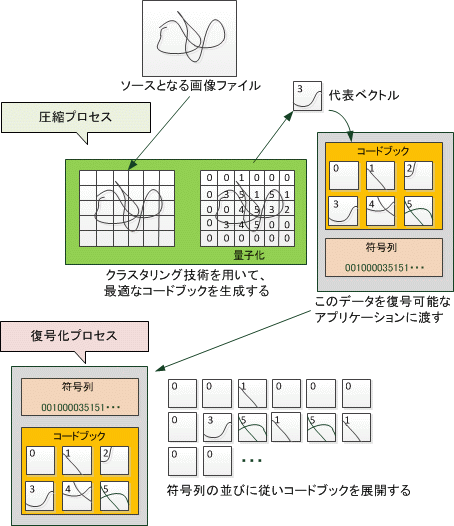
図2. VQを用いた画像処理アプリケーションのイメージ
なお、入力ベクトルからクラスタを作るクラスタリング手法には、LBG法(Linde-Buzo-Gray法)やPNN法(Pairwise Nearest Neighbor法)などがあります。(図3)
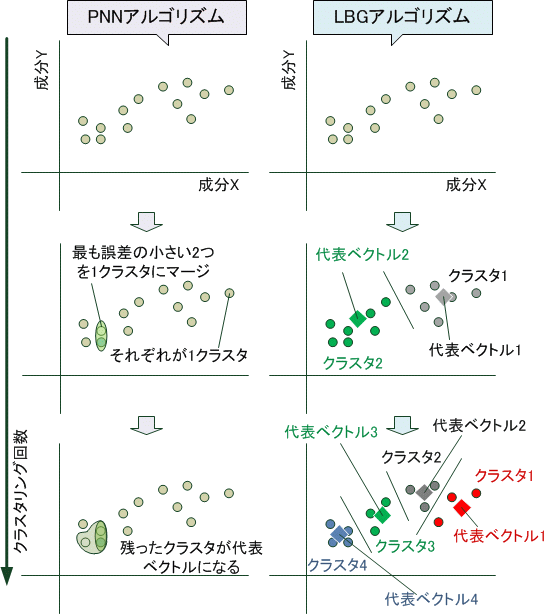
図3. 2次元ベクトルに対するクラスタリング技術の例
このように、VQとは情報圧縮や、情報に含まれている特徴の抽出に有用な技術です。
VQの基本的な考え方や用途などが明らかになるにつれ、VQの開発の歴史も明らかになってきました。その結果、意外と古くから存在する技術であることもわかりました。
VQは、「情報理論の父」と呼ばれる米国のクロード・シャノン(Claude E. Shannon)氏の「個々のサンプルではなく、ベクトルやシンボルの組をまとめて符号化すると、符号化システムの効率が良くなる」という発想から生まれたとされています。
VQが技術的に利用可能になったのは、電子機器の発達と低コスト化が進んだ1980年代からです。この頃、日本国内でもテレビのアナログ信号の空間的な符号化技術へ応用するための研究が行われています。その後、LBGアルゴリズムの発案により多様な情報へ応用可能になったことで、様々な動画像の情報圧縮手法としても注目されるようにもなりました。
1990年、動画圧縮で初の国際標準であるH.261を定める際に、VQと、現在JPEG画像等に用いられているDCT(Discrete Cosine Transform:離散コサイン変換)方式は、符号化処理の手法として競合していました。結果的に、H.261とその後に定められたMPEG-1での規格では、DCT方式が採用されました。仮に、この場でVQが採用されていれば、VQは現在の圧縮手法の定番になっていたでしょう。
画像圧縮技術としてVQを見た場合、どのような特徴があるのでしょうか。ここではVQを用いて画像ファイルを作成したと仮定して、JPEGなどの主要な画像フォーマットと比較してみましょう。
下記表 1に、VQを画像圧縮に用いたと仮定して、主要な画像フォーマットと比較をしてみました。
| フォーマット | BMP | GIF | PNG | JPEG | VQ |
|---|---|---|---|---|---|
| 圧縮アルゴリズム | (非圧縮) | LZ77を改良したLZWアルゴリズム | LZSS(LZ77の改良形)とハフマン符号化を組み合わせたDeflateアルゴリズム | DCT処理とエントロピー符号化を組み合わせたアルゴリズム | LBGやPNN等のクラスタリング手法を用いたベクトル量子化アルゴリズム |
| 可逆性 | (非圧縮) | ○ | ○ | × | × |
| 長所 | ・非圧縮のためノイズレス | ・可逆性 ・色数が少なく、同一色の傾向の強い画像ほど高圧縮 |
・可逆性 ・多彩な色彩表現が可能 ・色数が少なく、同一色の傾向の強い画像ほど高圧縮 |
・圧縮率を調整可能 ・多彩な色彩表現が可能 ・広く普及しており汎用性に富む |
・圧縮率を調整可能 ・多彩な色彩表現が可能 ・画像の展開速度が速い |
| 短所 | ・非圧縮のためファイルサイズが大きい | ・256色しか表現できず、それを超える色数の画像は圧縮時に劣化する | ・JPEGと同等の画質の場合、ファイルサイズがJPEGより数倍ほど大きくなりやすい | ・非可逆性 ・圧縮率によってはブロックノイズやモスキートノイズが生じる |
・非可逆性 ・ブロックノイズが生じる ・圧縮処理に時間がかかる |
| 適する用途 | ・ノイズレスで画質重視の場合 ・編集途中の画像 |
・線画や図形等 ・ウェブページ上のアイコン等 ・色数の少ない画像 |
・線画や図形等 ・色数の少ない画像 ・編集途中の画像 |
・風景写真 ・色数の多い画像 |
・線画や図形等 ・非常に解像度の大きい画像 |
表1. 主要な画像フォーマットとVQの比較
主要な画像フォーマットとして、BMP(非圧縮)、GIF、PNG、JPEGが良く知られています。このうち、GIFフォーマットやPNGフォーマットの圧縮アルゴリズムの元となっているLZ77は、1977年に発表された「辞書圧縮」などと表現される手法です。これは、「現在圧縮しようとしている部分に、すでに圧縮した部分と同じ文字列が存在すれば、それと置き換える」という方法で、一連の情報の中に同じ情報が含まれている画像ほど効果を発揮します。PNGフォーマットでは、さらにハフマン符号化処理を加えることで、ファイルサイズをより縮小できるよう工夫されています。
JPEGフォーマットはDCTを用いた圧縮手法で、以下の手順で圧縮が実行されます。
JPEGフォーマットは、写真等に良く使用されており、その汎用性は大きな強みです。加えて、保存時に圧縮率を調整できることも利点の一つです。
一方で、JPEGフォーマットの欠点は、圧縮率を高めた時に生じるブロックノイズとモスキートノイズです。前者は8×8ブロックに画像を細分すること、後者はDCT方式を用いて空間周波数に変換した際に生じるノイズです。特に後者のモスキートノイズとは色調が急激に変化する部分へ「蚊の大群が集まっている」ように見えるノイズのことで、PNGフォーマットなどに比べ、線画や図形には向いていません。
さて、それではVQを画像フォーマットに応用します。図 4と図 5は、ソフテックのホームページに掲載されている本社社屋写真について、モノクロ画像へのVQを施した例になります。ウェブ上に掲載するために、VQ実行後にJPEG画像として出力している点にご注意ください。
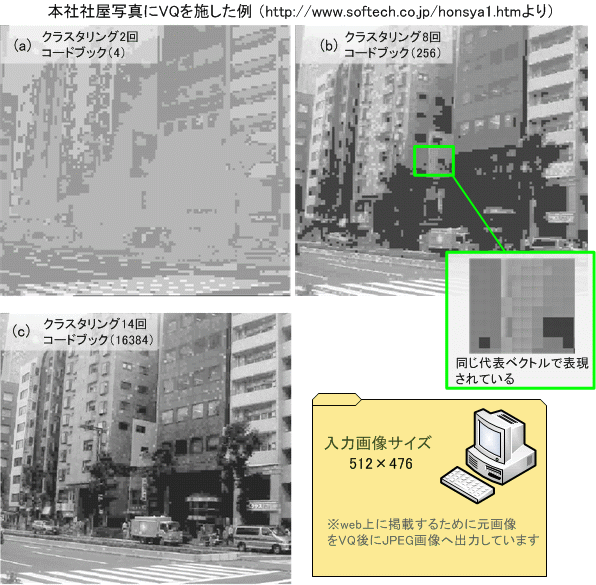
図4. 画像ファイルにVQを施した例
図 4は、純粋なLBGアルゴリズムを用いて、それぞれ2回、8回、14回のクラスタリングを行い、4、256、16384のコードブックを生成したものです。また、図 5にVQ画像と原図のJPEG画像の比較を示しました。
図4では、クラスタリングで算出したコードブックの数によって画質が大きく異なります。このように、VQ画像では圧縮率の調整が可能です。しかし、VQ画像はクラスタリング回数を増やすと、処理時間が指数関数的に増大します。これは算出するクラスタが2のべき乗で増加するためです。そのため、圧縮速度の高速化は、VQの研究命題の一つになっています。また、この試作プログラムでは、多くの論文で述べられるLBGアルゴリズムのクラスタリング性能限界に達しており、(c)以上の画質は得られませんでした。
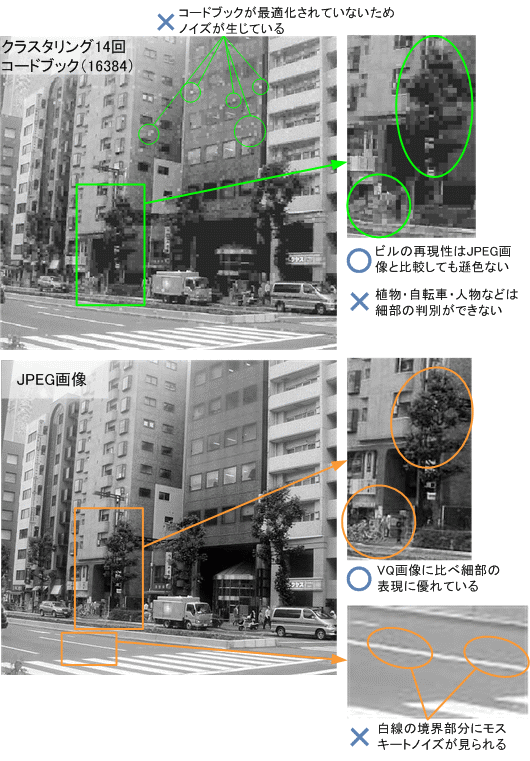
図5. VQ画像(上)とJPEG画像(下)の比較
VQ画像の利点は、以下の事柄から見えてきます。まず、今回のVQ画像において、コードブックは一つ4×4ピクセルで構成されています。図 5を見ると、コードブックのサイズよりもはるかに大きい建物は、JPEG画像とほぼ同等の画質が得られましたが、人物や自転車等、細部の再現性には劣っています。
次に、ピクセル数ごとのVQ画像とJPEG画像のデータサイズを表 2に示しました。VQ画像のファイルフォーマットは、200バイトのファイルヘッダと、コードブック・符号列を持つボディから構成されると仮定します。ボディは「1コードブックあたりのバイト数(16byte)×コードブック数+1符号あたりのバイト数(2byte)×全符号長」として計算を行いました。なお、比較対象として、一般的なアプリを用いて画質重視のモノクロ画像として出力したJPEG画像のデータサイズも掲載しました。
VQ画像は、コードブック数にも依存しますが、1000×1000ピクセル前後からJPEG画像より小さいデータサイズとなり、2000×2000ピクセル以上では明らかな優位性を示します。一方で、1000×1000ピクセル以下のデータサイズはJPEG画像よりも大きくなります。
これらの結果から、VQ画像が大きな解像度の画像圧縮に適していることがわかります。
| ピクセル数 | VQ画像 | JPEG画像 | |
|---|---|---|---|
| (コードブック数4092) | (コードブック数16384) | ||
| 256×256 | 72kb | 264kb | 35kb |
| 500×500 | 95kb | 287kb | 93kb |
| 1000×1000 | 186kb | 378kb | 204kb |
| 2000×2000 | 552kb | 744kb | 1672kb |
| 3000×3000 | 1163kb | 1355kb | 4359kb |
表2. VQ画像とJPEG画像のデータサイズ比較
VQは、処理時間の問題という解決すべき課題があり、いまだ研究途上の技術と言えます。これまでの研究で、VQは比較的単純な符号化技術であるにもかかわらず、多様な情報へ優れた符号化性能を示すことが明らかにされています。加えて、VQの符号化性能は理論的にレート歪み(※1)の限界にいくらでも近づけられると証明されています。2000年代に入り、高画質画像の高圧縮状況下(300分の1)において、実用的でJPEGより優れた画質を示すアルゴリズムが開発されるなど、精力的に研究が進められてきました。従って、VQは圧縮アルゴリズムの進化とハードウェアの発展も相まって、今後、より重要な技術になっていくと考えられます。
今回のソフテックだよりでは、VQの特徴や歴史などについてまとめました。現在、私たちは試作プログラムを作成するまでに至っており、今後はお客様のご期待に応えられると考えています。これまで調査主体に進めてきましたが、毎日新しい発見がありました。VQの今後の動向に注目していきたいと思います。
最後までお読みいただきありがとうございました。
(Y.T.)
関連ページへのリンク
関連するソフテックだより
「ソフテックだより」では、みなさまのご意見・ご感想を募集しています。ぜひみなさまの声をお聞かせください。