株式会社 ソフテック
制御用ソフトウェアの受託開発を手がけて54年の経験と
受注案件7415件(2026年6月末時点)の実績
受注案件7415件(2026年6月末時点)の実績
「ソフテックだより」では、ソフトウェア開発に関する情報や開発現場における社員の取り組みなどを定期的にお知らせしています。
さまざまなテーマを取り上げていますので、他のソフテックだよりも、ぜひご覧下さい。
ソフテックだより(発行日順)のページへ
ソフテックだより 技術レポート(技術分野別)のページへ
ソフテックだより 現場の声(シーン別)のページへ
「ソフテックだより」では、みなさまのご意見・ご感想を募集しています。ぜひみなさまの声をお聞かせください。
ここ数年でCPUの性能は飛躍的に向上し、高速クロック、大容量のROM/RAMを搭載できるCPUが多くなりました。その結果、マイコン用ソフトウェア開発(組み込みソフトウェア開発)において、リソース(※1)が不足する状況が少なくなってきたと感じます。しかし、消費電力を抑える必要があるシステムや、大量生産することを前提としたシステムの場合、CPUクロック周波数が低く、ROM/RAM容量が少ない、安価なCPUを使用します。このようなCPUを使用する場合は、処理速度、ROM/RAM容量に十分注意して開発を進めなければなりません。
今回の「ソフテックだより」では、処理速度にテーマを絞り、マイコン用ソフトウェアの高速化のポイントについて紹介します。なお、開発言語はC言語を前提とし、文章中のプログラムはNECの8ビットCPU 78K0/Kx2シリーズを前提として、CC78K0
V3.70でコンパイルした結果を使用します。
高速なマイコン用ソフトウェアを実現するために、設計時にどのようなことを行えば良いのか紹介します。
CPUの内蔵周辺機能には、タイマ、シリアル通信、A/D変換器などの機能がありますが、設計時にその内蔵周辺機能をどのような用途に使用するのか、割り込み優先度をどうするのか、リソース割り当てを決める必要があります。ここでしっかり設計を行っておかなければ、タイマが足りない、要求仕様の精度が実現できないなどの問題が発生し、大幅な手戻りが発生します。
また、全ての動作をプログラムで処理する必要はありません。CPUで出来ることはCPUに任せることで、大幅に処理速度を向上させることができます。例えば、モーター制御やLEDの輝度調整はパルス出力で行いますが、タイマ機能のタイマ出力を使用することで、プログラムの実行負荷に依存しない正確なパルス出力を行うことが出来ます。タイマ出力を例にあげましたが、決められたCPU端子に制御ハードを割り当てなければならないため、リソース割り当てはハードウェア設計者とも相談して決める必要があります。
RAMは大きく分けて、CPU内蔵の内部RAMと、外付けの外部RAMがあります。外部RAMはバス接続となるため、外部RAMのアクセスが多くなれば、それだけ処理速度も低下します。
そのため、割り込み処理などの速度が求められる処理で使用するデータや、頻繁にアクセスするデータは、内部RAMに配置する必要があります。
CPUで使用できる命令(MOV命令やADD命令などのアセンブラレベルの命令)の種類や、Cコンパイラの性能によって処理速度の予測がずれることがあります。ハードウェアが完成して動かしてみたら予測した処理速度が得られていないという状況では大幅な手戻りが発生します。
Cコンパイラの設定でアセンブラリスト出力設定を行い、出力されたアセンブラコードの命令クロック数から処理時間を求められます。速度が求められる割り込み処理などは、プロトタイプを作成して、おおよその処理時間を算出しておくことをお勧めします。
割り込み処理時間のワーストケースで、全ての割り込み要因が同時に発生した場合でも、全ての割り込み処理を処理できるかを確認する必要があります。図1のような割り込みタイミングチャートを作成することで、同時に割り込み要因が発生した場合に、どのくらい割り込み処理実行が保留されるのか、割り込みが実行されない期間がどのくらいあるのかを確認することが出来ます。
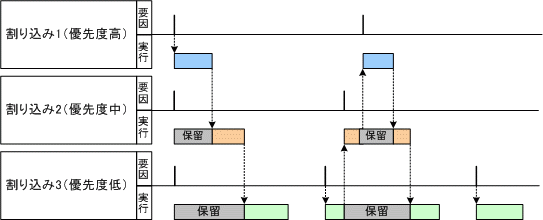
図1. 割り込みタイミングチャート
割り込み処理時間が長くなれば、それだけ他の処理が実行できなくなるため、割り込み処理はできるだけ短い処理時間で終える必要があります。
割り込み処理については、ソフテックだより第89号「マイコン用ソフトウェアの割り込み処理」で紹介していますので、あわせてご覧ください。
割り込みが入ったとき、割り込み内で使用するレジスタをスタックに待避し、割り込みを抜けるときにスタックから復帰します。レジスタの退避・復帰の時間はC言語のコード上では目に見えません。レジスタの退避・復帰はCPUやCコンパイラに依存するため、オーバーヘッド時間(※2)がどの程度なのかを把握する必要があります。Cコンパイラから出力されたアセンブラリストからオーバーヘッド時間を求めることが出来ます。
また、一般的には割り込みは、命令と命令の区切り目で受け付けられるため、除算命令などの時間がかかる命令が実行されている場合は、割り込みが待たされるので、その時間もオーバーヘッド時間として考慮する必要があります(命令を中断して割り込みを受け付けるCPUもあります)。
割り込み処理に伴うレジスタの待避・復帰を高速に行うためのレジスタ・バンク(※3)を備えているCPUもあるため、レジスタ・バンクがある場合は、レジスタ・バンク指定することで、オーバーヘッド時間の短縮が可能です。
図2はレジスタ・バンクを使用しない場合と使用した場合のC言語ソースです。このC言語ソースをコンパイルして得られたアセンブラ結果が図3になります。コメントにクロック数を記載していますが、レジスタ・バンクを使用することで12クロック(CPUクロック10MHz時は1.2μ秒)の高速化ができています。
図2. オーバーヘッド時間の改善(C言語)
図3. オーバーヘッド時間の改善(アセンブラ)
以前に使用したCPUでは、必要のないレジスタの退避が数十バイトも行われており、オーバーヘッド時間が200μ秒(CPUクロック2MHz)になっていたことがありました。そのときは、割り込み処理の入り口をアセンブラで記述し、必要なデータの待避のみを行うことでオーバーヘッド時間を30μ秒に短縮できました。このように、オーバーヘッド時間を把握することは非常に重要になります。
通常処理と割り込み処理で、共通のデータ変数を使用する場合には、排他制御(割り込み禁止)を行ってからデータ変数を使用します。排他制御時間が長ければ、それだけ割り込みが待たされることになり、通信処理の場合は、受信データの取りこぼしとなることもあります。そのため、排他制御は必要コード部分のみとし、排他制御時間を短くする必要があります。
複数の割り込みを使用している場合は、全割り込み禁止とせずに対象の割り込みだけを割り込み禁止とすることで、他の割り込みを実行することができます。ただし、多重割り込みを使用している場合は、高優先の割り込みを割り込み禁止とした場合に、低優先の割り込みは受け付けられるため、割り込み優先条件が崩れることになります。多重割り込みを使用する場合は注意が必要です。
割り込み処理の実行時間は極力短くする必要があります。割り込み周期の短い割り込みや、割り込み優先度の高い割り込みは特に注意が必要です。
例えば、通信の受信割り込みでは、受信データをバッファに格納するだけにし、データ解析処理は通常処理で行うなど、割り込み処理では必要最低限の処理だけを行い、処理時間を短くします。
その他の注意事項について紹介します。
高速なCPUを使用する場合、CPUで使用できる命令を意識してプログラミングすることはほとんどありませんが、少しでも処理速度の速いプログラムを作成する場合は、CPUで使用できる命令を意識する必要があります。
CPUによっては、除算命令やバレルシフト命令(※4)がないCPUもあり、C言語で記述されたコードからCコンパイラが除算命令やバレルシフト命令の代わりとなるアセンブラロジックを生成します。そのロジックの実行分、処理速度が低下します。
一般的にC言語では、ポインタを使用してアクセスすることで処理の高速化ができますが、CPUやCコンパイラによってはポインタアクセスのプログラムにすることで処理速度が低下することもあります。
以下はその例ですが、図4の左側のC言語ソースはで、ポインタを使用して10バイトのバッファコピーを行っています。このC言語ソースをコンパイルして得られたアセンブラ結果が右側のソースになります。一部省略して記載していますが、16ビットのアドレス空間を8ビットのレジスタに取り出してコピーしていることで、1バイトのコピーにアセンブラで20命令以上使用しています。コメントに命令クロック数を記載していますが、1バイトのコピー部分だけで142クロックあり、10バイトのコピーでは単純計算で1420クロックです。CPUクロック10MHzの場合、142μ秒の処理時間になります。
図4. 処理速度改善前
図5の左側のC言語ソースは改善後のソースですが、データコピーを代入で行い、10バイト分の代入文を並べました。このC言語ソースをコンパイルして得られたアセンブラ結果が右側のソースになります。省略して記載していますが、1バイトのコピーが16〜28クロックであり、10バイトのコピーに要する命令クロック数は250クロックでした。CPUクロック10MHzの場合、25μ秒の処理時間です。図4のソースに比べて、117μ秒もの短縮ができています。
仮に、データ変数g_byBufが割り込み処理で使われている場合、排他制御が必要となりますが、3(2)で説明したとおり、排他制御時間を短くする必要があります。性能が低いCPUの場合、117μ秒は大きな改善です。
きれいなコードの書き方ではありませんが、処理速度向上のために必要になる時もあります。
図5. 処理速度改善後
どのようなコンパイル結果になるのかを把握せずにプログラミングした結果、大幅な速度差が出ることになります。このような実例があるので、実際にCコンパイラでアセンブラリストを出力して、アセンブラコード内容を確認することをお勧めします。
マイコン用ソフトウェアの高速化について説明しましたが、今回あげた内容の他にも高速化するテクニックはいくつもあると思います。
最近は、アセンブラを使用して開発することは少なくなりましたが、CPUで使用できる命令を把握し、C言語のコードからどのようなアセンブラコードが出力されるのかを確認するケースはまだあります。そのため、「ある程度」はアセンブラコードを読めたほうが良いです。
今回は、性能が低いCPUを想定した紹介内容ですが、高速なCPUの場合でも、リソースを意識する必要があります。リソースを意識せずにプログラムを作った結果、思っていたよりパフォーマンスが出ていないということも少なくありません。また、完成時点で問題がなくても、仕様変更が入ることでリソースが不足する自体にもなりかねません。マイコン用ソフトウェアは、パソコンのように簡単にリソースを追加・変更できないので、CPUの性能が十分であっても、リソースを無駄に消費しないプログラム作りを心がける必要があります。
(M.A.)
関連ページへのリンク
関連するソフテックだより
「ソフテックだより」では、みなさまのご意見・ご感想を募集しています。ぜひみなさまの声をお聞かせください。